De la idea a la implementación: creación de una función de IA personalizada para la descripción de imágenes
Con nuestro agente de IA, puedes ir más allá de las acciones estándar del editor y añadir funciones personalizadas adaptadas a tus necesidades. Esta publicación explica el proceso de creación de la función describeImage y cómo convierte imágenes en títulos, pies de foto y texto alternativo accesible.

La idea
El objetivo es sencillo: seleccionar una imagen, proporcionar una breve instrucción y recibir el texto generado exactamente donde lo necesitas. La función admite casos de uso comunes como títulos de imágenes, pies de foto y texto alternativo, evitando suposiciones sobre la intención del usuario al basarse en indicaciones explícitas.
Diseño de la función
Para que la función esté disponible en el motor de IA de ONLYOFFICE, se definió como una RegisteredFunction. Esta definición especifica el nombre de la función, los parámetros esperados y ejemplos de indicaciones que demuestran su uso previsto.
let func = new RegisteredFunction({
name: "describeImage",
description:
"Allows users to select an image and generate a meaningful title, description, caption, or alt text for it using AI.",
parameters: {
type: "object",
properties: {
prompt: {
type: "string",
description:
"instruction for the AI (e.g., 'Add a short title for this chart.')",
},
},
required: ["prompt"],
},
examples: [
{
prompt: "Add a short title for this chart.",
arguments: { prompt: "Add a short title for this chart." },
},
{
prompt: "Write me a 1-2 sentence description of this photo.",
arguments: {
prompt: "Write me a 1-2 sentence description of this photo.",
},
},
{
prompt: "Generate a descriptive caption for this organizational chart.",
arguments: {
prompt:
"Generate a descriptive caption for this organizational chart.",
},
},
{
prompt: "Provide accessibility-friendly alt text for this infographic.",
arguments: {
prompt:
"Provide accessibility-friendly alt text for this infographic.",
},
},
],
});
Esta definición cumple dos propósitos:
- Informa al motor de IA de ONLYOFFICE sobre las capacidades de la función y la entrada esperada.
- Proporciona ejemplos de uso para guiar tanto a la IA como a los usuarios finales.
Implementación de la lógica
El método call contiene la funcionalidad real que se ejecuta cuando el usuario invoca la función:
- Recuperar la imagen seleccionada: mediante GetImageDataFromSelection, obtenemos la imagen del documento. También filtramos las imágenes de marcador de posición para garantizar resultados de IA significativos.
- Construir la indicación para la IA: la instrucción del usuario se combina con el contexto de la imagen seleccionada para crear una indicación clara y accionable.
- Verificar la compatibilidad del modelo de IA: solo los modelos con capacidades de visión (como GPT-4V o Gemini) pueden procesar imágenes. Se alerta al usuario si su modelo actual no admite imágenes.
- Enviar la solicitud a la IA: la imagen y la indicación se envían al motor de IA mediante chatRequest, recopilando el texto generado en tiempo real.
- Insertar el texto generado por la IA en el documento: la función detecta si hay una imagen seleccionada o no e inserta el resultado en el lugar correspondiente.
- Manejo de errores: la función gestiona de forma elegante la ausencia de imágenes, los modelos no compatibles o errores inesperados de la IA, proporcionando mensajes claros al usuario.
1. Obtención de la imagen seleccionada
En ONLYOFFICE, las imágenes dentro de un documento se tratan como drawings (dibujos). Para procesar una imagen seleccionada por el usuario, utilizamos la API de plugins de ONLYOFFICE:
let imageData = await new Promise((resolve) => {
window.Asc.plugin.executeMethod(
"GetImageDataFromSelection",
[],
function (result) {
resolve(result);
}
);
});
- GetImageDataFromSelection es un método del plugin de ONLYOFFICE que extrae la imagen seleccionada actualmente como una cadena codificada en Base64.
- El resultado es un objeto, normalmente con esta estructura:
{
"src": "data:image/png;base64,iVBORw0K...",
"width": 600,
"height": 400
}
Esta cadena src contiene la imagen completa en formato Base64, que puede enviarse directamente a modelos de IA que aceptan datos de imagen.
Consideraciones clave:
- Si no hay ninguna imagen seleccionada, imageData es null.
- Algunos usuarios pueden seleccionar gráficos de marcador de posición o rectángulos vacíos. Por ejemplo, ONLYOFFICE utiliza un pequeño rectángulo blanco como marcador de posición para imágenes vacías. Lo comparamos con su representación en Base64 para filtrarlos y evitar resultados irrelevantes:
const whiteRectangleBase64 = "data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAAEAAAABCAYAAAAfFcSJAAAADUlEQVR42mP8/5+hHgAHggJ/PchI7wAAAABJRU5ErkJggg==";
if (imageData.src === whiteRectangleBase64) {
console.log("describeImage: Image is white placeholder");
await insertMessage("Please select a valid image first.");
return;
}
2. Preparación de la imagen para la IA
Los modelos de IA esperan las imágenes como URLs o como datos codificados en Base64, normalmente en un campo como image_url. En nuestra función, enviamos la imagen junto con una indicación textual en un arreglo estructurado:
let messages = [
{
role: "user",
content: [
{ type: "text", text: argPrompt },
{
type: "image_url",
image_url: { url: imageData.src, detail: "high" },
},
],
},
];
- type: «text» proporciona las instrucciones del prompt (por ejemplo, «Añadir un pie de foto descriptivo»).
- type: «image_url» incluye la imagen en sí. El motor de IA puede entonces analizar la imagen y generar el texto correspondiente.
- detail: «high» es una pista opcional para que los modelos procesen la imagen en resolución completa.
Lógica de transformación:
- ONLYOFFICE proporciona src como una cadena en Base64.
- Los modelos de IA pueden aceptar datos en Base64 una URL accesible. En este caso, usamos Base64 directamente para evitar subir la imagen a un servidor externo.
- Envolvemos la imagen en un objeto compatible con la API de solicitudes de chat de la IA. Esta estructura permite combinar varios tipos de contenido en un solo mensaje.
3. Envío de la solicitud a la IA
Una vez que tenemos la imagen y el prompt estructurados, utilizamos el motor del plugin de IA de ONLYOFFICE:
let requestEngine = AI.Request.create(AI.ActionType.Chat);
await requestEngine.chatRequest(messages, false, async function (data) {
console.log("describeImage: chatRequest callback data chunk", data);
if (data) {
resultText += data;
}
});
- AI.ActionType.Chat permite enviar mensajes de tipo chat, donde la indicación y la imagen se analizan conjuntamente.
- El callback recopila fragmentos del texto de respuesta de la IA en tiempo real.
- Antes de enviar la solicitud, comprobamos si el modelo de IA seleccionado admite visión. Solo ciertos modelos (como GPT-4V o Gemini) pueden procesar imágenes:
const allowVision = /(vision|gemini|gpt-4o|gpt-4v|gpt-4-vision)/i;
if (!allowVision.test(requestEngine.modelUI.name)) {
console.warn("describeImage: Model does not support vision", requestEngine.modelUI.name);
await insertMessage(
"⚠ This model may not support images. Please choose a vision-capable model (e.g. GPT-4V, Gemini, etc.)."
);
return;
}
4. Inserción de la salida de la IA en el documento
Después de recibir la salida de la IA, el texto debe insertarse de nuevo en el documento de ONLYOFFICE. La lógica contempla dos casos:
- Imagen seleccionada: insertar un párrafo después de la imagen.
- Ninguna imagen seleccionada: insertar un párrafo después de la posición actual del cursor.
async function insertMessage(message) {
console.log("describeImage: insertMessage called", message);
Asc.scope._message = String(message || "");
await Asc.Editor.callCommand(function () {
const msg = Asc.scope._message || "";
const doc = Api.GetDocument();
const selected =
(doc.GetSelectedDrawings && doc.GetSelectedDrawings()) || [];
if (selected.length > 0) {
for (let i = 0; i < selected.length; i++) {
const drawing = selected[i];
const para = Api.CreateParagraph();
para.AddText(msg);
drawing.InsertParagraph(para, "after", true);
}
} else {
const para = Api.CreateParagraph();
para.AddText(msg);
let range = doc.GetCurrentParagraph();
range.InsertParagraph(para, "after", true);
}
Asc.scope._message = "";
}, true);
- Api.GetSelectedDrawings() recupera las imágenes (dibujos) seleccionadas actualmente.
- Api.CreateParagraph() crea un nuevo objeto de párrafo.
- InsertParagraph(para, «after», true) inserta el texto generado inmediatamente después de la imagen o del párrafo seleccionado.
- Esto garantiza una integración fluida: la salida de la IA siempre aparece en el contexto correcto.
5. Manejo de casos límite y errores
Algunos desafíos requirieron atención adicional:
- Ninguna imagen seleccionada: pedir al usuario que seleccione una.
- Modelo de IA no compatible: advertir al usuario antes de enviar la solicitud.
- Respuesta vacía de la IA: notificar al usuario que la IA no pudo generar una descripción.
- Errores inesperados: usar bloques try/catch anidados para finalizar de forma segura cualquier acción en curso del editor:
} catch (e) {
try {
await Asc.Editor.callMethod("EndAction", ["GroupActions"]);
await Asc.Editor.callMethod("EndAction", [
"Block",
"AI (describeImage)",
]);
} catch (ee) {
}
Esto asegura que el documento permanezca estable incluso si la IA o el plugin fallan a mitad de la operación.
Resultado final
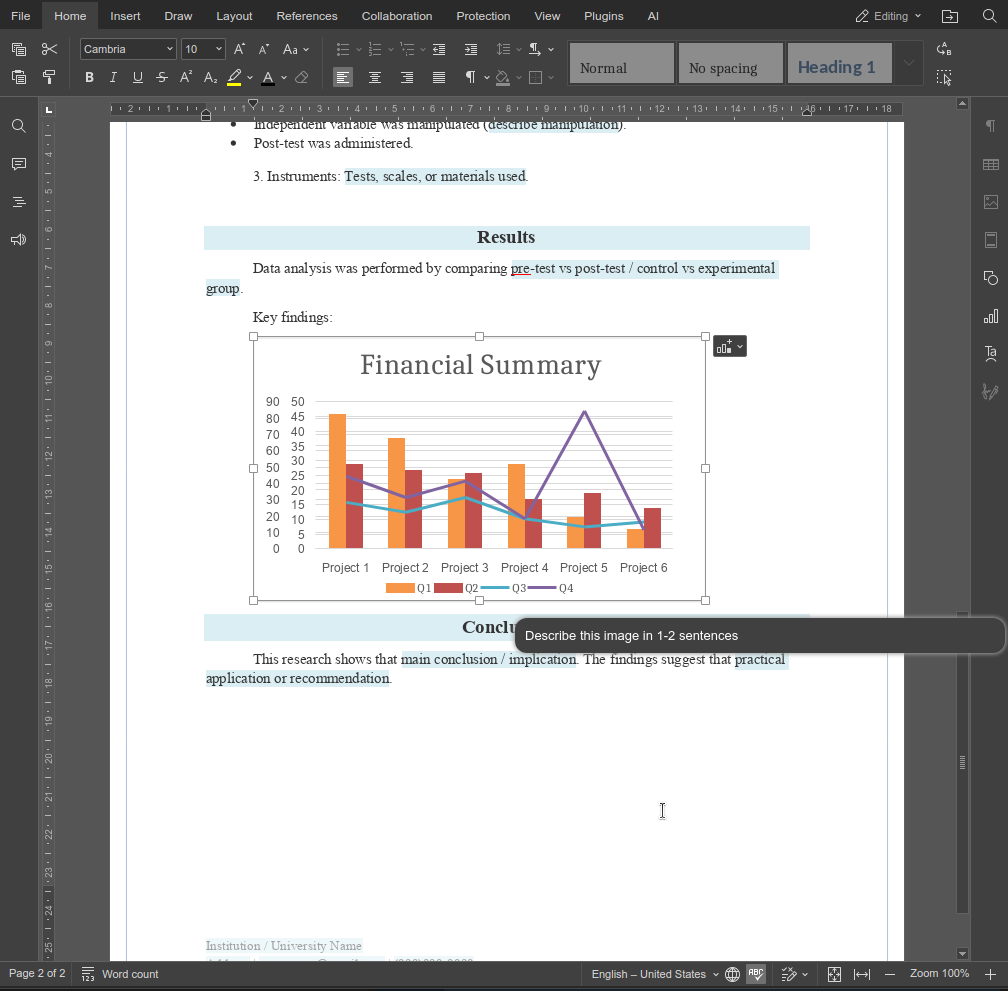
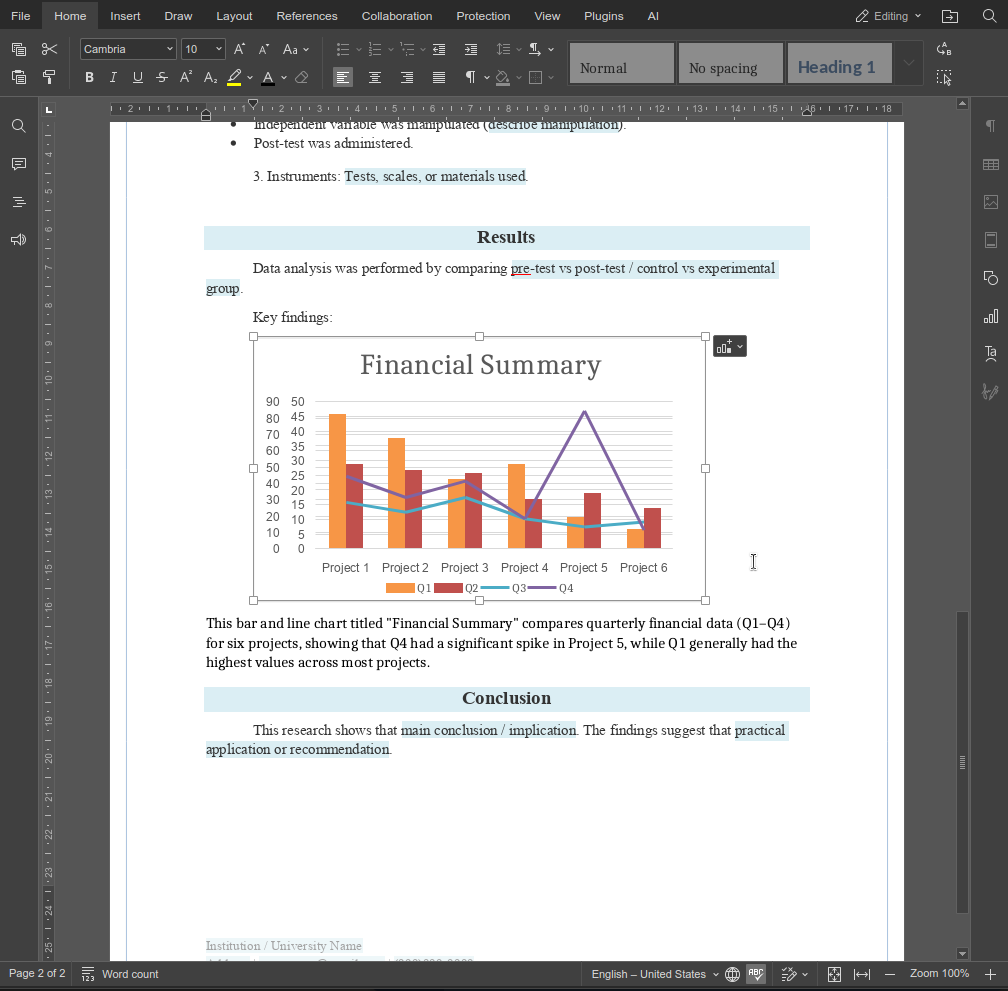
La función describeImage describeImage demuestra cómo las funciones personalizadas pueden ampliar el agente de IA de formas pequeñas pero de alto impacto. Al combinar indicaciones claras con una lógica consciente del editor, es posible crear funciones que se integren directamente en flujos de trabajo reales, en lugar de acciones genéricas de IA.
Prueba a crear tus propias funciones personalizadas para adaptar la funcionalidad de nuestro agente de IA. Si desarrollas algo útil, no dudes en compartirlo con nosotros a través de página de contacto.
Crea tu cuenta gratuita de ONLYOFFICE
Visualiza, edita y colabora en documentos, hojas, diapositivas, formularios y archivos PDF en línea.


